Prompt Pack Refinement: Distilling UI Agent Failures into Reliable Computer Use Agents
Nen turns existing desktop applications into infrastructure agents can reliably use.
Today we're sharing prompt pack refinement, an inference-time technique that turns agent failures on recurring UI workflows into compact, reusable instructions that improve reliability without retraining the model.
In our experiments on healthcare administration tasks, refined packs improved both accuracy and run-to-run consistency, while raw traces of prior successful runs degraded performance. This post explains the approach and early lessons.
How prompt pack refinement works
Prompt pack refinement is an inference-time technique that turns repeated UI-agent failures into compact workflow guidance. The pack is text that the agent sees at inference time.
The unit of work is a skill: one workflow on one application. Each skill ships as a SKILL.md with frontmatter (name, description, when-to-use) and a body of natural-language guidance. At inference time the agent's system prompt is composed of an app-level system SKILL.md (UI conventions, common pitfalls of the application) plus the workflow-level SKILL.md.
A pack captures the parts of a workflow that should not have to be rediscovered on every run: procedure order, UI element names, common false paths, application-specific quirks, and recovery rules.
The loop starts with real failures, not a task description:
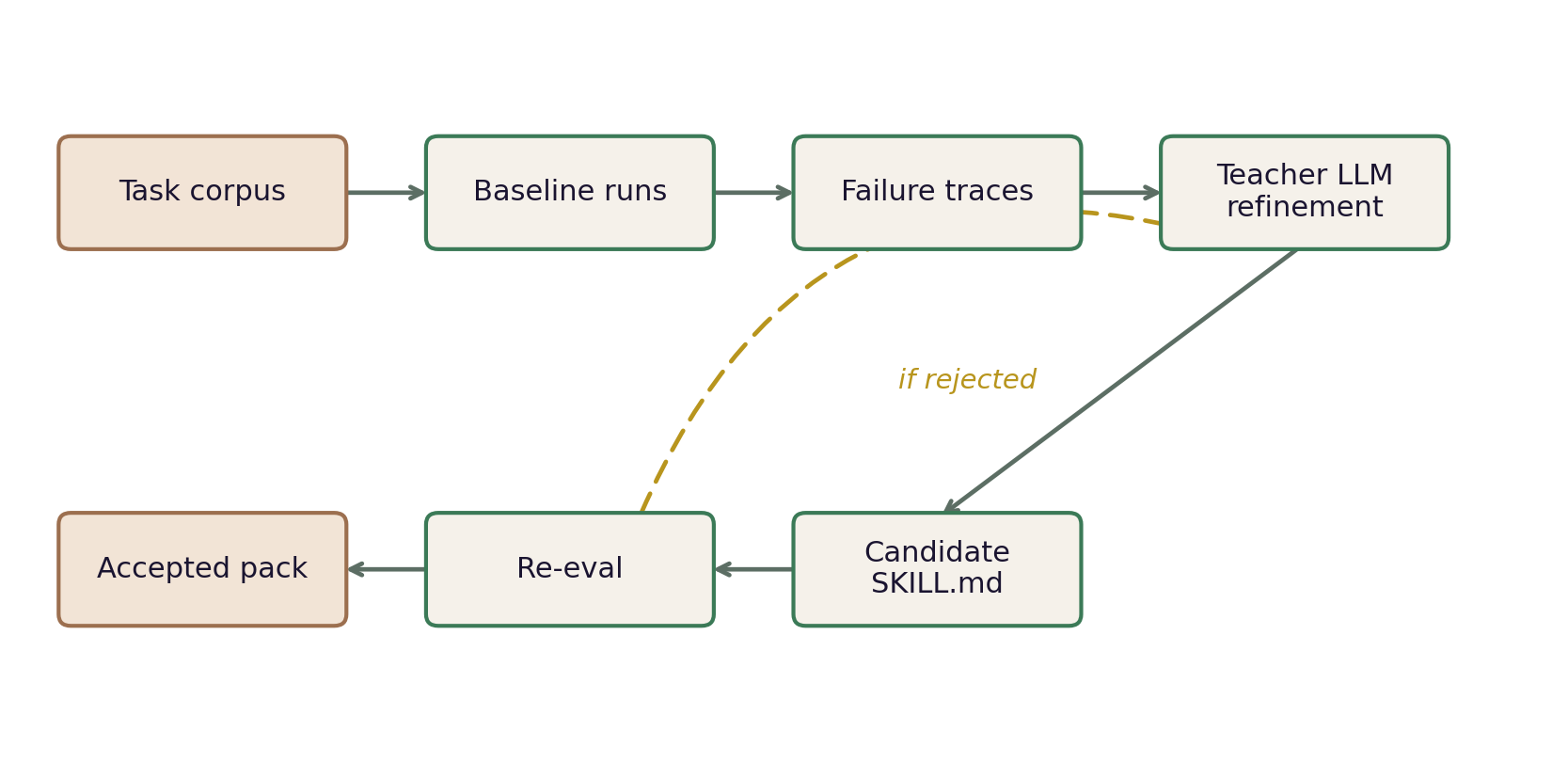
Task corpus. Per skill we curate task instances that share a coherent workflow shape and vary on workflow-relevant axes. The point is data variation on a single workflow shape, not training across different workflows.
Baseline eval. Run the agent against the train set with no pack, only the agent's bare default behavior. The failure traces from this run become the input to the first refine call.
Refine. A teacher LLM reads the agent's actual failure traces and diagnoses what went wrong. It then writes or edits the workflow pack, addressing the specific failures the agent exhibited: wrong page, wrong field, wrong order, brittle recovery, or a false path that looked plausible in the UI.
Iterate. Re-test the candidate SKILL.md. Accept the edit only when it improves behavior; otherwise reject it and try another edit. Stop when train passes or the iteration cap is reached.
In production we run the distillation loop N times in parallel and ship the highest-scoring converged pack — a small implementation detail that makes the deliverable robust against single-run sampling variance in the teacher LLM.
Why this architecture
Desktop automation is reasoning-sensitive. OSWorld and WindowsAgentArena leaderboards show a wide gap between frontier reasoning models and faster, cheaper ones on identical workflows. Reasoning at inference time is doing real work.
That creates a deployment economics problem: the most reliable agent on a workflow is often also the most expensive one to run. Prompt packs may help amortize that reasoning across repeated workflows by making recurring constraints explicit.
There are two broad ways to improve an agent on a recurring UI workflow: change the model, or change what the model sees. For recurring workflows, we want the agent to get better without shipping a new model for every customer workflow. That points us toward token-space learning: improve the workflow instructions the model sees at inference time, while leaving the model weights alone.
The observations behind prompt packs
Three observations motivate the project:
-
Workflow guidance is a UI-agent reliability lever. A system prompt that specifies UI element names, procedure ordering, and known failure modes helps close the gap between demo-feature and production-grade execution.
-
The workflows customers care about repeat. A revenue cycle clerk processing referrals does the same 8-step procedure thousands of times per week, with patient/payer/procedure varied. A pack that captures the procedural shape once amortizes across every instance.
-
A good pack may help lighter models have the performance of larger models. Large frontier models often do better on UI automation because they spend more reasoning on the workflow. A prompt pack gives the model the recurring constraints up front, so it does not have to rediscover them mid-trajectory. This can narrow the reliability gap on repeated workflows.
The alternative is weight-space learning: fine-tuning, RLHF on rollouts, or distilled policies trained on workflow-specific trajectories. Those methods can work, but they add trajectory collection, GPU time, a separate model artifact per workflow, and migration work as base models change.
Prompt packs are lighter-weight. A new production failure can update the text artifact the same day, using the same refinement loop we use during training. There is no retraining job, no model-weight versioning, and no separate checkpoint to migrate when the frontier model changes.
Where we ran this
Most of the early work is on HealthAdminBench (HAB), a Stanford-published benchmark for medical revenue-cycle workflows on a synthetic EHR. HAB tasks cover recurring healthcare administration workflows and include verifiable per-criterion evals: state-grounded queries against the harness, not text-grep on agent output.
HAB was the natural starting point because the workflows repeat, the environment is reproducible, and the evals can check what happened in the application state. For example, for "triage a referral and document the prior-auth determination," tasks vary by patient, payer, plan, procedure, and diagnosis while preserving the same workflow shape.
The results in this post come from a single workflow group within HAB covering durable medical equipment intake and prior-auth submission. Within that group, we curated a task corpus that varies on workflow-relevant axes (patient, payer, plan, procedure, document set) while keeping the procedural shape constant. Some tasks are happy paths where the agent should run the workflow end-to-end; others are clinical-gating tasks where the agent should recognize that the workflow does not apply and refuse to run it.
3-arm ablation. After distillation converges, we run all three arms on a held-out test set:
| Arm | What the agent gets | What it tests |
|---|---|---|
| A | No pack | Baseline ability |
| B | Raw prior traces | Whether examples alone help |
| C | Refined SKILL.md | Whether curated guidance helps |
A is the floor. C - A is what the pack contributes. B exists to distinguish curated guidance in a refined prompt pack (Arm C) from pure examples alone (Arm B, "just gave it more data").
Note that HAB is healthcare-specific, and this work is still early. Our runs cover only 4 of HAB's 21+ subcategories so far. Whether the patterns generalize across domains is an open question.
Cost: distillation amortizes; frontier inference doesn't
The deployment-economics argument depends on a specific shape: Sonnet's per-run cost is the same on the millionth workflow as on the first, while a pack-distilled Haiku deployment pays a fixed upfront distillation cost that amortizes as the workflow runs.
For the workflow group above, the math works out like this1:
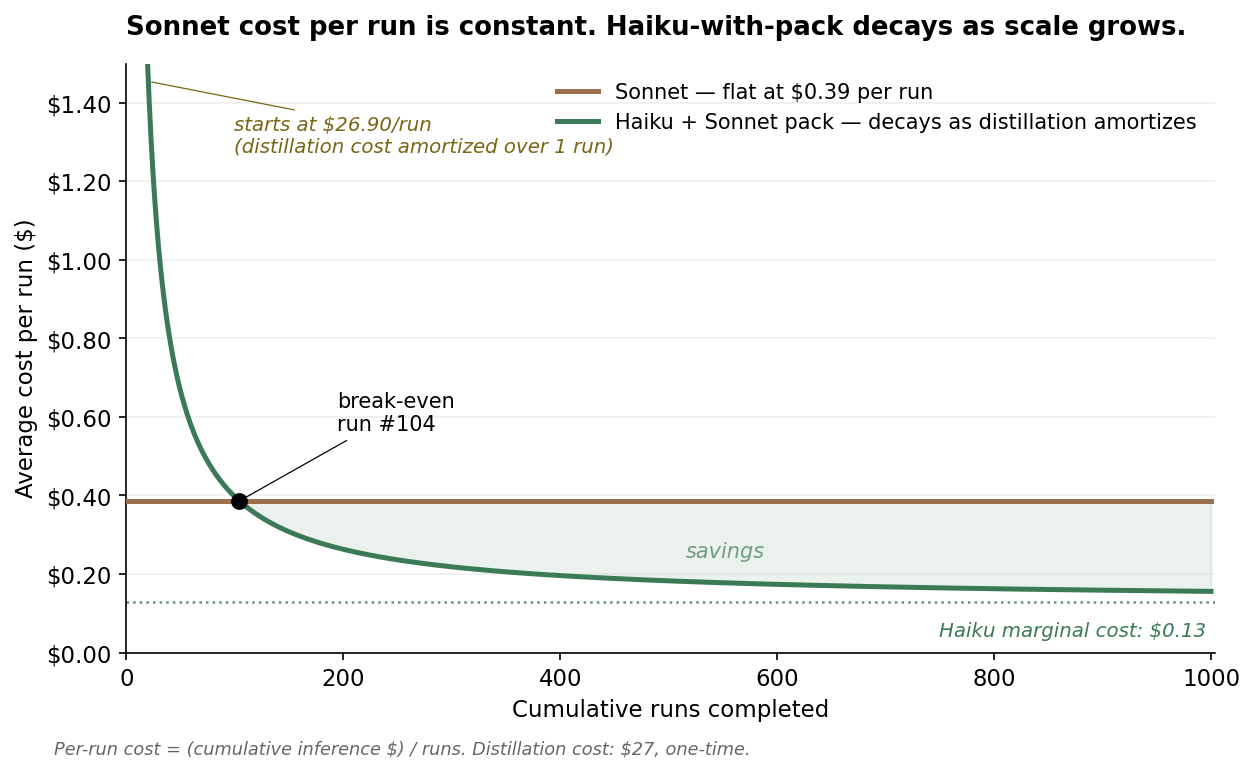
A pack distilled on Sonnet costs about $27 to produce — 49 Sonnet agent traces plus 7 teacher-LLM refinement passes. Once it exists, every production run uses Haiku-4.5 at roughly one-third the per-token cost of Sonnet-4.6. The upfront $27 means Haiku-with-pack starts more expensive than Sonnet on a per-run basis, but break-even arrives at about 104 runs, and at production scale (1,000+ runs of the same workflow per week, which is realistic for a revenue-cycle clerk) the per-run cost approaches Haiku's marginal floor of about $0.13.
Lessons from prompt pack refinement
Lesson 1: Raw traces are not the same as distilled workflow guidance
Arm B, the raw-trace arm, is designed to test whether examples alone help. So far, the signal is that raw episode telemetry is a poor substitute for distilled workflow guidance. Raw traces include the agent's mid-task confusion, false starts, and recovery moves. When fed back as examples, those details can muddy the working signal.
Arm C, the refined pack arm, strips the noise and keeps the load-bearing instructions: do this, avoid that, the relevant UI element is named X. The refined pack arm's value is the curation, not just the data.
The Haiku ablate isolates the contribution of curation. The "raw traces" arm (Arm B) gets the same successful trajectories the refiner sees, dropped into the system prompt as examples. The "refined pack" arm (Arm C) gets the curated SKILL.md the refiner wrote from those same trajectories.
Haiku 4.5, held-out test (3 tasks × 3 runs):
bare Haiku 67.2%
+ raw Sonnet traces 69.3% (+2.1pp from examples alone)
+ refined Sonnet-distilled pack 77.2% (+10.0pp — curation adds 7.9pp)Arm B suggests examples alone get you a small lift. Arm C shows that the compression and selection that turns a multi-thousand-token trajectory into a few hundred tokens of "do this, avoid that" is where most of the gain lives.
Lesson 2: Packs help when there is failure signal, and can hurt when there isn't
Refinement needs something real to learn from. If Arm A, the baseline, already passes most tasks, the teacher has too little failure signal and writes brittle instructions where there was nothing useful to write about. The risk isn't just that Arm C, the refined pack arm, is neutral. It can actively regress performance by encoding train uniformities as rules the agent then over-applies.
The clearest evidence comes from running the same workflow against Sonnet on two task mixes. On a happy-path-only mix, the bare Sonnet baseline in Arm A clears the test set, so the refined pack arm has nothing useful to refine and looks flat. But add clinical-gating tasks where the right answer is to recognize the workflow does not apply and refuse to run it, and Arm C actively regresses:
Sonnet 4.6 on 3 happy-path + 2 gating test tasks (3 runs per arm):
bare + raw traces + refined pack
Aggregate (5 tasks) 90.7% 87.8% 88.0%
Happy-path tasks (3 of 5) ~100% ~100% ~100%
Gating task fax-hard-5 60% 47% 40%Bare Sonnet gets ~60% partial credit on the gating task because it correctly refuses some of the procedural steps that don't apply. Arm C drops to 40% because the refined pack encoded "do the fax workflow" rules from happy-path training data and overrides the model's correct gating decision.
Two practical implications. First, when a model is already at ceiling on the training distribution, refinement has no real failures to learn from and can do net damage by promoting test-setup uniformities into rules. Second, when the workflow includes gating decisions, the refined pack must be told about them explicitly, or it learns "always run the procedure" from training data where the procedure always applies.
Lesson 3: Description-driven bootstrap is risky
An earlier version of the loop had a bootstrap step that fed a short task description to the teacher model and asked for an initial runbook before any failures had been observed. That created brittle guidance: the teacher imagined failure modes, inferred UI details that were not actually present, and wrote preventive rules the agent then followed too literally.
We dropped that path. Refinement now drafts and edits packs from real failure traces, not from a task description alone.
Lesson 4: Hill-climbing optimization is sensitive to task statefulness
Prompt pack refinement is a hill-climbing optimization: each iteration proposes a candidate edit and accepts it only if it improves train pass-rate. Like any hill-climbing method (sometimes called quality hill climbing in industry, discrete search or greedy local search in academic taxonomies), the loop optimizes the signal it can measure (pass rate on a fixed corpus) rather than the underlying objective the signal is meant to track (workflow capability that generalizes). Where those diverge, the optimizer encodes the divergence as a rule.
The most common form of divergence on UI workflows is hidden state: parts of the train environment that are correlated with success but aren't actually part of the task. The harness's starting URL, a pre-loaded patient context, a session token that's always present at episode start, an application that always opens to the same tab — none of these are visible as task inputs, but they all show up identically in every train trace. Hill-climbing on train pass-rate will happily promote these uniformities into the pack as rules.
One converged pack contained the line "You are already at
/emr/worklist. Do NOT attempt to navigate to a different URL."
That was true for every train task because the harness loaded each
episode at that URL. In production, where the agent could start from
elsewhere, the instruction could mislead.
The broader point is that refinement learns from whatever stays constant in the traces. If every train run starts from the same URL, the pack may treat that URL as part of the workflow. The fix is partly review and partly better data: audit packs for rules that could not have failed on train, and vary irrelevant state in the train set when you can.
Production experience helps on this and similar cases because real deployments surface the weird start states, stale sessions, and UI detours that a clean benchmark can hide.
Where this applies
Prompt pack refinement is most useful when a workflow is:
- repeated across many similar cases
- run through an existing UI
- sensitive to small procedural mistakes
- expensive to run with a high-reasoning model every time
- stable enough that workflow guidance can amortize across future runs
Examples include prior authorization and referral triage in healthcare revenue cycle, carrier portal updates in logistics, KYC and exception review in financial services, and batch-record review in pharma QC.
Closing
Prompt pack refinement is one part of how Nen makes computer use agents reliable on recurring workflows.
If your agent needs to operate the same desktop workflow thousands of times, the answer probably is not to paste more traces into context. It is to distill the workflow into the smallest set of instructions that changes behavior.
If you are building agents for real enterprise UIs, we'd like to talk.
Footnotes
-
Per-run cost modeled from wall-clock × per-step token estimates for tasks of approximately 20–60 steps per attempt. The distillation cost ($27) and the per-run model rates (Haiku 4.5 at $1/$5 per million input/output tokens, Sonnet 4.6 at $3/$15) are Anthropic May 2026 list pricing. ↩